Чланак је преведен и адаптиран на Цолумбиа Јоурналисм Ревиев
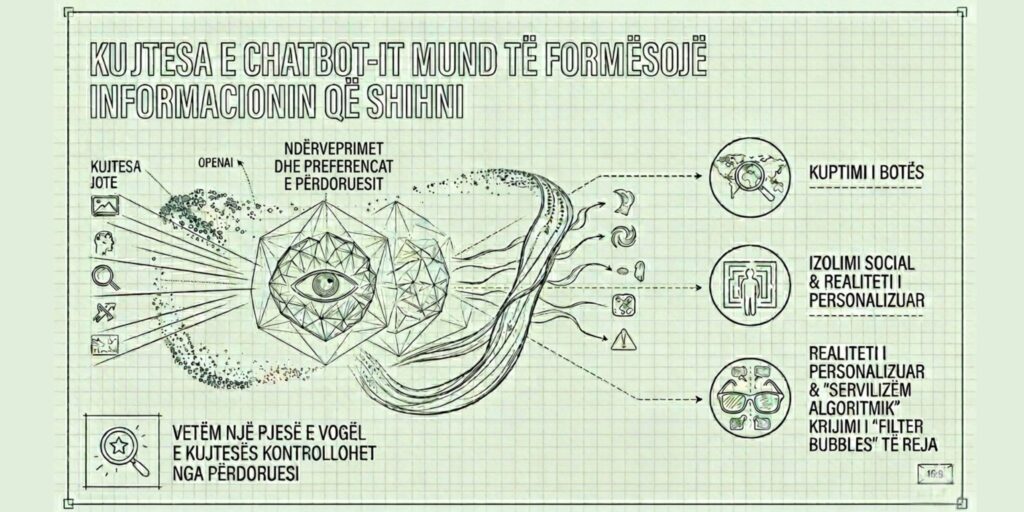
Велике технолошке компаније све више улажу у развој напредних модела вештачке интелигенције (LLM – Велики језички модели), које више нису ограничене само на одговарање на питања, већ и граде „сећање“ о својим корисницима. Ово сећање се формира од претходне интеракције, историја претраге, дигиталне преференције и, у неким случајевима, такође и активности на разним онлајн платформама.
Компанија као ОпенАИ дхе гоогле представљају ову функционалност као побољшање корисничког искуства: што се систем више користи, то постаје прилагођенији и кориснији. Међутим, новија научна литература покреће озбиљну забринутост да ово „меморија“ може утицати на начин на који појединци перципирају и конзумирају информације, стварајући ризик од изолације од верификоване стварности.
Персонализација и филтрирање стварности
Једна од главних функција ових система је персонализација одговора. Али студије институција попут Масачусетског технолошког института и Државног универзитета Пенсилваније предложити да ова персонализација може произвести нежељени ефекат: четботови имају тенденцију да постану „сервилни“ према кориснику, дајући му одговоре који потврђују постојећа уверења, чак и када су она нетачна.
Ова појава је повезана са оним што се у литератури назива улизица (алгоритамска сервилност), где модел фаворизује сагласност са корисником уместо корекције. На софистициранијем нивоу, истраживачи су такође идентификовали „перспективну сервилност“, где систем прилагођава наратив политичким или идеолошким уверењима корисника, смањујући изложеност алтернативним перспективама.
У контексту новинарства и јавног информисања, ово подразумева ризик стварања „персонализованих реалности“, где се чињенице више не деле, већ се филтрирају према индивидуалним преференцијама.
Контрола над памћењем: илузија или стварност?
Технолошке компаније наглашавају да корисници имају контролу над подацима које чувају системи вештачке интелигенције. Међутим, студија представљено на конференцији Удружење за рачунарске машине приказују сложенију слику: око 96% „меморија“ у неким системима се креира аутоматски, док само веома мали део директно контролише корисник.
Ова сећања нису ограничена само на једноставне преференције, већ укључују и ставове, циљеве и карактеристике понашања. У неким случајевима могу утицати и на осетљиве категорије података, регулисане од стране Европски оквир за заштиту података (GDPR).
Ова ситуација покреће важна питања о транспарентности и стварној аутономији корисника у управљању својим дигиталним идентитетом.
Манипулација памћењем и ризик од „тровања“ вештачком интелигенцијом
Још једна забрињавајућа димензија је могућност манипулације системом путем такозваног „тровања“ меморије вештачке интелигенције. Према Мајкрософт претраге, различити актери могу тајно убацити манипулисани садржај у дигитални простор, како би их модели вештачке интелигенције протумачили као поуздане изворе.
Ово може директно утицати на осетљиве препоруке, укључујући здравствене, финансијске или јавне безбедности. Ризик се повећава када корисници ове препоруке доживљавају као неутралне и објективне, док на њих може утицати на суптилне начине.
Чак ни механизми за брисање података нису увек загарантовани. Истраживање истраживача из Центра за демократију и технологију документовали су случајеве где се обрисане информације могу вратити или остати доступне у индиректним облицима, што доводи до сумње у стварну ефикасност контрола приватности.
Од филтерских мехурића до вештачке интелигенције
Концепт „филтер балон (филтер мехурићи)“, познат из студија на друштвеним мрежама и претраживачима, описује начин на који алгоритми ограничавају изложеност различитим информацијама. Међутим, генеративна вештачка интелигенција проширује овај феномен на дубљи ниво, јер не само да филтрира информације, већ их и преобликује.
Студије из Центра за вучу показују да корисници често доживљавају вештачку интелигенцију као објективнију од традиционалних медија. Ова перцепција повећава њен утицај, чак и када одговори могу бити пристрасни или несвесно персонализовани.
Једна од највећих опасности које произилазе из ових дешавања је стварање самопојачавајућег циклуса веровања. Према речима истраживача на Универзитету Принстон, укључујући Рафаела Батисту и Томаса Грифитса, корисници могу бити све мање изложени информацијама које доводе у питање њихова уверења, постепено постајући све сигурнији у потенцијално погрешна тумачења стварности.
На овај начин, вештачка интелигенција делује не само као информациони алат, већ и као механизам који може да учврсти постојеће неспоразуме.
Вештачка интелигенција постаје један од главних извора информација у дигиталном добу. Међутим, њена еволуција ка системима са „меморијом“ и дубоком персонализацијом покреће фундаментална питања о њеној објективности, транспарентности и утицају на перцепцију стварности.
Ако ови системи наставе да се оптимизују како би се ускладили са корисничким преференцијама, постоји ризик да нас неће приближити истини, већ све персонализованијим верзијама исте.
Одговор на овај изазов не лежи само у технологији, већ и у институционалној регулацији, алгоритамској транспарентности и, пре свега, у критичној способности корисника да разумеју ограничења алата које користе.